Creating nonlinear neural network and finding the Jacobian matrix of its funciton
The next step towards finding loss function of a neural network is to extend the results we found here to add a bias to the linear function, i.e., creating $W^{\top}x+b$ where $x \in \mathbb{R}^n$, $b \in \mathbb{R}^m$, and $W \in \mathbb{R}^{n \times m}$. This can be done easily because we already have the part of a network that generates $W^{\top}x$. It suffice to add a constant vector to the previous result. Therefore, we have the follwing for the case where $n = 2$ and $m = 3$
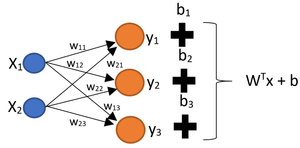
Now to create a nonlinear function $F(x)=f( W^{\top}x+b)$, we need to pass in the above quantity to the function $f$, which produces $F(x)$.
Jacobian matrix of $F(x)=f( W^{\top}x+b)$
A relevant question at this moment is how we can find the Jacobian of $F(x)$ using what we learned in this post and the other one. We know Jacobian matrix of a composite function is the product of Jacobians so
$$
J_F(x) = J_{f}(W^{\top}x+b)J_{W^{\top}x+b}(x) = J_{f}(h)\circ (W^{\top}x+b) J_{W^{\top}x+b}(x)
$$
where $h = W^{\top}x+b$. Note that Jacobian of $f$ is being taken with respect to $h$. In neural networks $f$ is a scalar function which is applied to each element of $h$ separately so we have the following
$$
f(h) =
\begin{bmatrix}
f(h_1)\\
f(h_2)\\
\vdots\\
f(h_m)
\end{bmatrix}
$$
According to what we have discussed here, $J_f(h)$ is all first-order partial derivatives of $f(h)$ as the following
$$
J_f(h)= \begin{bmatrix}
\frac{\partial f(h_1)}{\partial h_1} & \frac{\partial f(h_1)}{\partial h_2}& \cdots& \frac{\partial f(h_1)}{\partial h_m}\\
\frac{\partial f(h_2)}{\partial h_1} & \frac{\partial f(h_2)}{\partial h_2}& \cdots& \frac{\partial f(h_2)}{\partial h_m}\\
\vdots & \vdots & \cdots & \vdots\\
\frac{\partial f(h_m)}{\partial h_1} & \frac{\partial f(h_m)}{\partial h_2}& \cdots& \frac{\partial f(h_m)}{\partial h_m}
\end{bmatrix}
=
\begin{bmatrix}
\frac{\partial f(h_1)}{\partial h_1} & 0& \cdots& 0\\
0 & \frac{\partial f(h_2)}{\partial h_2}& \cdots& 0\\
\vdots & \vdots & \cdots & \vdots\\
0 & 0& \cdots& \frac{\partial f(h_m)}{\partial h_m}
\end{bmatrix}
$$
It is remarkable that because of the structure that we define for the neural network, we get a diagonal matrix for the Jacobian of $J_f(h)$ where each element of its diagonal is functionally the same but is being represented by different variables. However, we are after $J_{f}(h)\circ (W^{\top}x+b)$ which says wherever we have one coordinate of $h$, i.e., $h_i$ where $i = 1, 2, \cdots, m$, substitute the coresponding coordinate of $W^{\top}x+b$.
$$
\begin{align}
J_f(h)\circ (W^{\top}x+b)
&=
\begin{bmatrix}
\frac{\partial f(h_1)}{\partial h_1} & 0& \cdots& 0\\
0 & \frac{\partial f(h_2)}{\partial h_2}& \cdots& 0\\
\vdots & \vdots & \cdots & \vdots\\
0 & 0& \cdots& \frac{\partial f(h_m)}{\partial h_m}
\end{bmatrix}\circ (W^{\top}x+b)\\
&=
\begin{bmatrix}
f'(h_1) & 0& \cdots& 0\\
0 & f'(h_2)& \cdots& 0\\
\vdots & \vdots & \cdots & \vdots\\
0 & 0& \cdots& f'(h_m)
\end{bmatrix}
=\phi'_f(h)
\end{align}
$$
where $\phi'_f(h)$ is defined as a digonal matrix whose diagonal is the derivative of $f$ at the corresponding coordinates of $h$.
From this post we know Jacobian matrix of $J_{W^{\top}x+b}(x)$ is just $W^{\top}$.
Therefore, $$
J_F(x) = J_{f}(h)\circ (W^{\top}x+b) J_{W^{\top}x+b}(x) = \phi'_f(h)W^{\top}
$$
In the following I am going to elaborate on a neural network that has more layer than input and output and derive its Jacobian matrix. Consifer the following network
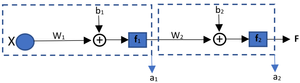
Using the above we can write
$$
\begin{align}
F(x)&=a_2\\
&= f_2(w_2^{\top}a_1+b_2)\\
F(x)&=
f_2(w_2^{\top}f_1(w_1^{\top}x+b_1)+b_2)\\
F(x)&=f_2\circ(w_2^{\top}u+b_2)\circ f_1( w_1^{\top}x+b_1)
\end{align}
$$
Since $a_1 = w_1^{\top}x+b_1$.
In order to find the Jacobian matrix with respect to the input we have to use the multiplication rule that we derived here. Therefore,
$$
\begin{align}
J_F(x)&= J_{f_2}(w_2^{\top} a_1 + b_2) J_{f_1}(w_1^{\top} x + b_1)\\
&= \phi'_{f_2}(a_2)w_2^{\top}\phi'_{f_1}(a_1)w_1^{\top}
\end{align}
$$
If you associate the above formula with the figure, you can conclude that no matter how many layers we have, the same pattern would repeat for them.
To recap what we have done so far, we can claim that by looking at the suppressed network, we can find the Jacobian matrix.